Basic Math Concepts – LeCun Initialization Applicability in Neural Network
The main goal is to preserve variance of activations across layers:
Formula:
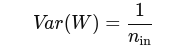
So that:
Summary
| Aspect | Explanation |
|---|---|
| Why LeCun? | Avoids gradient vanishing for tanh/sigmoid activations |
| When to use? | Shallow networks or activations like tanh/sigmoid |
| Stock Use Case Fit | Works well in shallow stock predictors with sliding windows (time series) |
| Math Core | Init weights with N(0, 1/nin) |
| Visual Difference | Loss decreases faster and smoother with LeCun Init |