Basic Math Concepts – L2 Regularization in Neural Network
L2 regularization adds a penalty term to the loss function:
Loss Without Regularization:
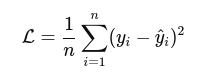
Loss With L2 Regularization:
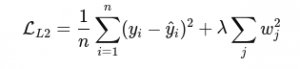
Where:
- λ is the regularization strength
- wj are the model’s weights
Why It Helps?
- Minimizing this loss not only makes predictions accurate but also keeps weights small.
- Small weights mean simpler models, which reduce overfitting.
Summary
| Aspect | Without L2 | With L2 |
|---|---|---|
| Loss | Just prediction error | Error + weight penalty |
| Weights | Can become large | Encouraged to stay small |
| Generalization | May overfit | Better on unseen data |
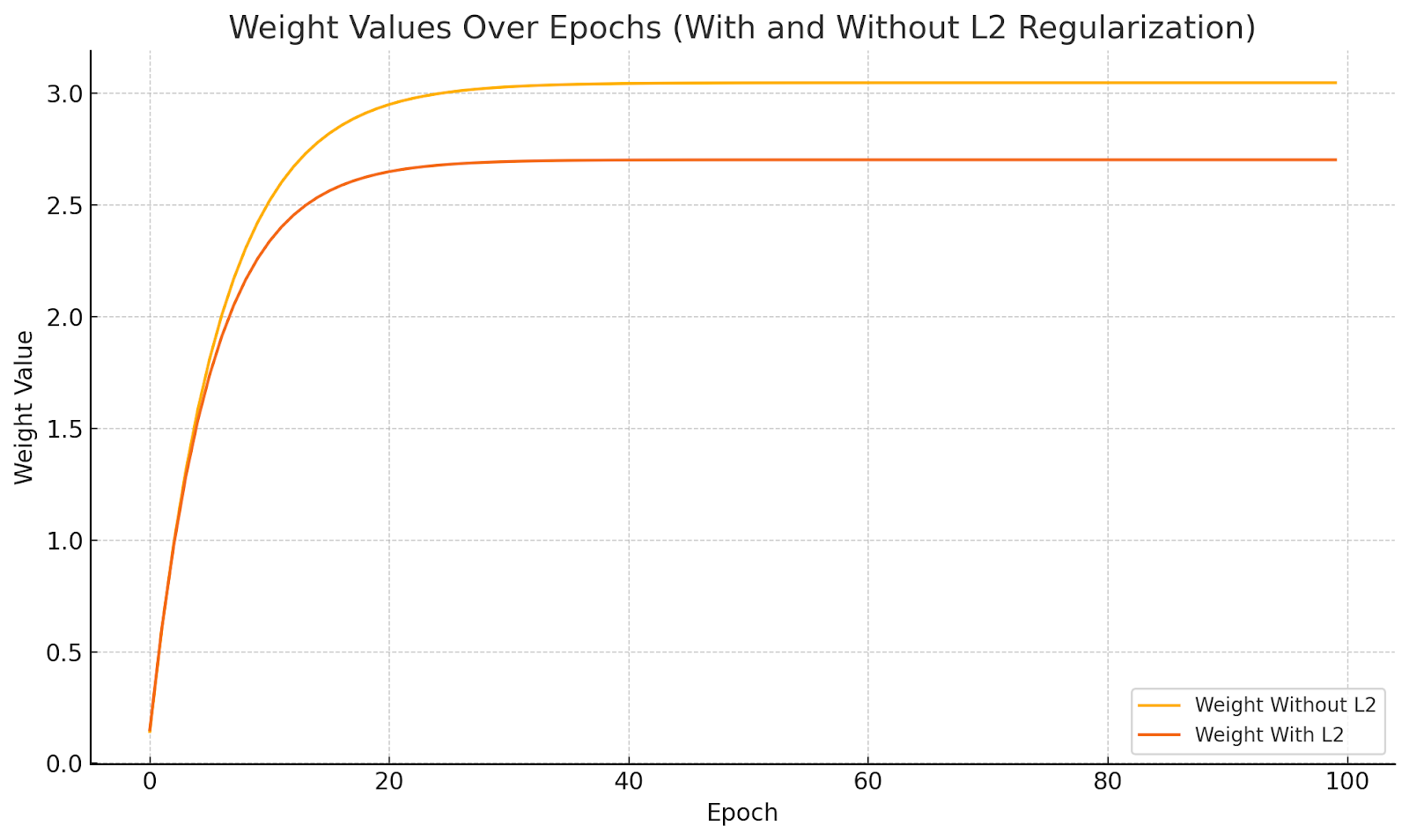
Here is the chart showing how the weight values evolve over epochs with and without L2 regularization:
- Without L2: The weights can grow larger as the model tries to minimize the error aggressively.
- With L2: The weight values are more controlled and converge smoothly, thanks to the regularization penalty.
Next – L1 Regularization vs L2 Regularization Selection for different use cases in Neural Network