Basic Math Concepts – Sparse Initialization Applicability in Neural Network
To understand sparse initialization, we should know:
| Concept | Explanation |
|---|---|
| Matrix | Neural weights are stored as matrices. |
| Sparsity | A matrix with many zero entries. If 70% are zero, sparsity = 0.7 |
| Dot Product | For forward pass, only non-zero weights contribute to the result. |
| Random Sampling | Picking a small subset of entries to initialize non-zero. |
Mathematical Expression: If W is the weight matrix:
- Sparse init:
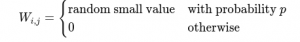
Where p is the non-zero proportion (e.g., 0.2 or 20%)
Why Not Use Dense Initialization Always?
| Sparse Initialization | Dense Initialization |
|---|---|
| Light on memory | Heavy memory usage |
| Faster at start | Slower on big data |
| Better for sparse data | Can overfit on sparse data |
| Less risk of exploding gradients | Higher risk if not careful |
Sparse Initialization Applicability in Neural Network – Visual Roadmap