Basic Math Concepts – Regularization in Neural Network
1. Mean Squared Error (MSE):
Used to measure prediction error:
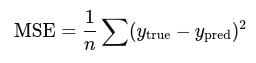
2. L2 Regularization (Ridge):
Penalizes large weights by adding a term to loss:
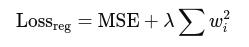
Where:
- λ: Regularization strength
- wi: Individual weights
3. Gradient Descent:
Updates weights using:
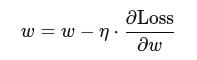
With regularization:
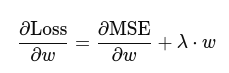
Summary
| Concept | Without Regularization | With Regularization |
|---|---|---|
| Overfitting | High chance | Reduced |
| Weights | Can grow large | Kept small |
| Generalization | Poor | Better |
| Loss Function | MSE only | MSE + weight penalty |
Here’s a visual chart showing how loss behaves over epochs with and without regularization:
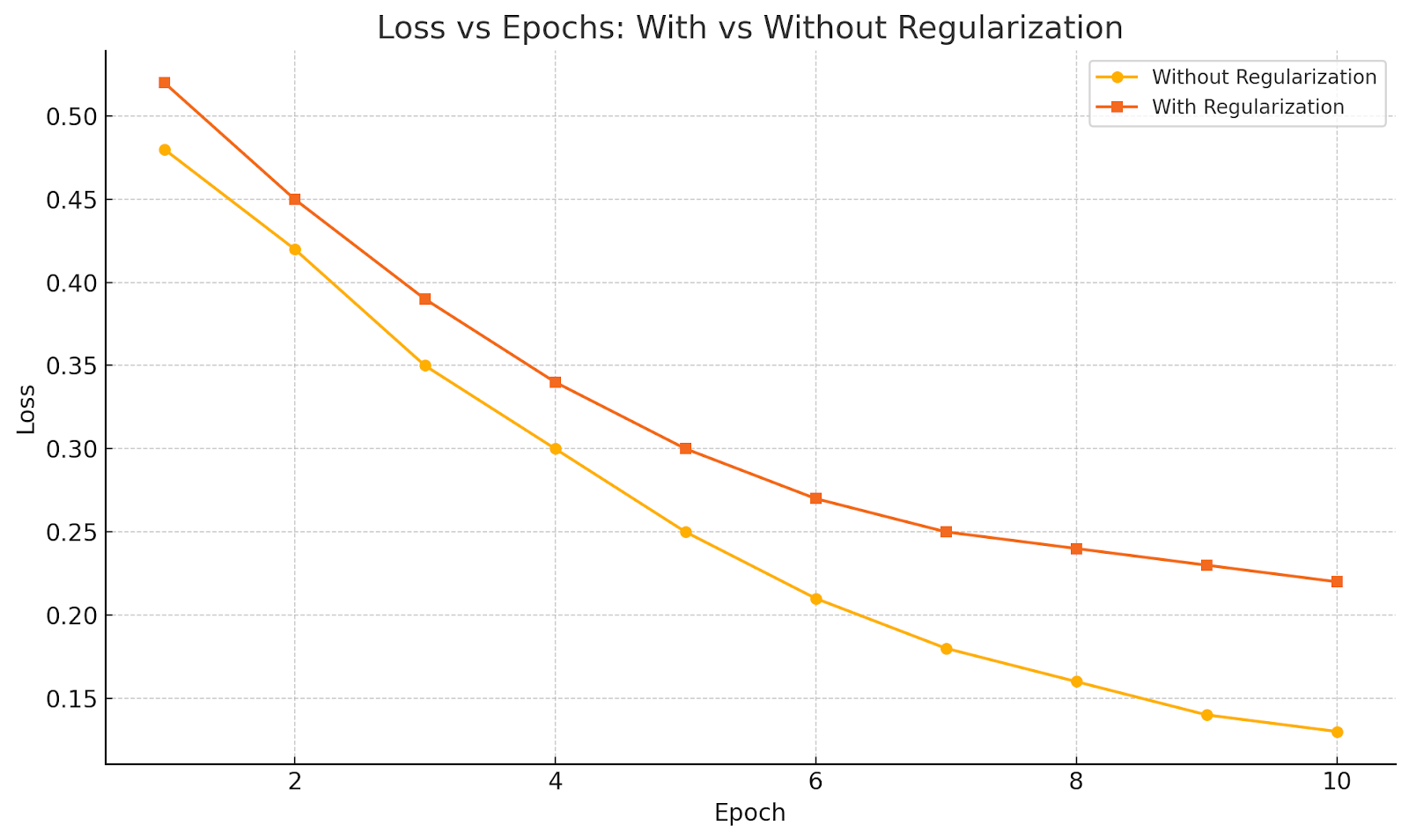
Explanation of the Chart
| Feature | Without Regularization | With Regularization |
|---|---|---|
| Loss Drop | Very sharp initially | Steady and smoother |
| Final Loss | Lower (but misleading) | Slightly higher (but stable) |
| Risk | May overfit – model memorizes | Lower overfitting – better generalization |
| Weight Growth | May become large | Penalized, remains controlled |
Key Insight
- Without regularization: The model quickly minimizes the training error, but might do so by over-relying on specific features (weights explode).
- With regularization: The model trades off a small increase in error for better simplicity and generalization.