Basic Math Concepts – L1 Regularization in Neural Network
Loss Function without Regularization:
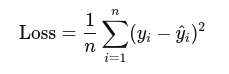
L1 Regularized Loss:
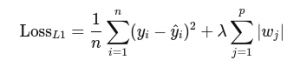
Where:
- λ: Regularization strength (how much penalty you apply)
- |wj|: Absolute value of weights
- ∑|wj|: Total penalty for all weights
This penalty shrinks weights and some even become exactly zero, making the model simpler and more interpretable.
Visual Summary:
| Concept | Description |
|---|---|
| Goal | Avoid overfitting by penalizing large weights |
| What it does | Adds absolute value of weights to loss |
| Result | Many weights become exactly zero (sparse model) |
| Benefit | Feature selection, model simplicity |
A chart showing how the loss decreases with and without L1 regularization visually.
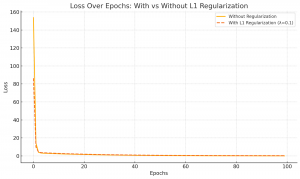
Here’s the chart comparing how the loss decreases over epochs with and without L1 Regularization:
- Orange Line: Training without any regularization — it may decrease fast but can overfit.
- Orange Dashed Line: Training with L1 Regularization — loss may reduce more gradually but leads to simpler and more generalizable models.
A chart showing how the weight value changes over time with L1 regularization visually.
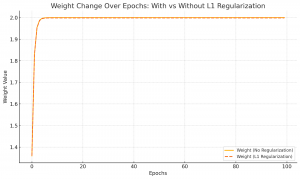
Here’s the chart showing how the weight value changes over time with and without L1 Regularization:
- Orange Line: Weight updates without regularization — may remain large and less controlled.
- Orange Dashed Line: Weight updates with L1 regularization — pulled toward zero gradually.