Basic Math Concepts – Prediction Error in Neural Network
The error is the basis for most loss functions.
1. Absolute Error:
Error = |y − y^|
2. Mean Squared Error (MSE):
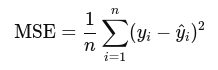
Used commonly in regression problems. Squaring ensures the error is always positive and penalizes large errors more.
Visualization Over Epochs
| Epoch | Predicted (ŷ) | Actual (y) | Error (y − ŷ) |
|---|---|---|---|
| 1 | 5.0 | 10 | 5.0 |
| 2 | 7.0 | 10 | 3.0 |
| 3 | 9.0 | 10 | 1.0 |
| 4 | 9.8 | 10 | 0.2 |
The error keeps reducing as training progresses.
1. Algebra
- Understanding linear equations like:
y = wx + b
- Variables, constants, coefficients
- Substitution and solving equations
2. Functions
- Concept of input → function → output
- Example:
f(x) = wx + b
- Understand how inputs are transformed through layers
3. Error Measurement (Distance Metrics)
- Difference between actual and predicted values:
Error = y − y^
- Squared error to penalize large errors:
Loss = (y − y^)^2
4. Calculus – Derivatives (Gradient)
Most important to understand how neural networks learn!
- How a function changes with respect to a variable:
D / dX(x^2) = 2x
- Derivative tells us the slope or direction to minimize error
- In neural nets:
- Derivative of loss w.r.t weight (∂L / ∂w) tells how to update the weight
- Weights are updated in the direction that reduces the loss
5. Gradient Descent
- Iterative method to minimize a function:
w = w − η⋅∂L / ∂w
where η is the learning rate
- It moves the weights in the negative gradient direction to reduce loss
6. Chain Rule of Calculus (for Multi-layer Networks)
- When functions are composed:
z = f(g(x)) → dz / dx = df / dg ⋅ dg / dx
- Essential in backpropagation through multiple layers
7. Mean and Averaging
- Loss is often averaged across samples:
MSE = 1 / n ∑(yi − y^i)^2
Summary Table
| Math Topic | Why It’s Needed in Neural Networks |
|---|---|
| Algebra | To define models (e.g., y = wx + b) |
| Functions | To understand how input maps to output |
| Error Measurement | To evaluate prediction accuracy |
| Derivatives | To calculate how error changes w.r.t parameters |
| Gradient Descent | To reduce error by updating weights |
| Chain Rule | To apply backpropagation across layers |
| Averages | To generalize loss over datasets |
Prediction Error in Neural Network – Summary