Neural Network Weight Change Impact in different stages
1. Story-Style Overview: The Neural Network Learning Journey
Imagine we’re training a neural network to guess if an email is spam or not.
- Initialization (Baby Brain): Like a newborn, the network starts with random weights — it knows nothing.
- Forward Pass (First Guess): It looks at features (e.g., “has link”, “capital letters”) and multiplies them with weights to make a guess — like: “Hmm, based on what I see, this email is probably 60% spam.”
- Loss Calculation (Teacher’s Feedback): A loss function compares the prediction (e.g., 0.60) with the true label (e.g., 1 for spam), and gives a score — the penalty for being wrong.
- Backpropagation (Learning from Mistakes): The network calculates how each weight contributed to the error and adjusts it slightly to reduce future mistakes.
- Repeat for All Emails (Practice Makes Perfect): Over thousands of examples, the weights get better — just like how we improve with feedback.
2. Weight Changes And impact :
We are training a neural network. Our weights decide how much importance we give to each input feature. These weights evolve at each processing step to improve prediction quality.
1.Weight Initialization (Start with a Blind Guess)
- Weight Values: Small random numbers (e.g., from np.random.randn)
- Why?: Prevent symmetry — each neuron needs a different path to learn uniquely
- Impact:
- Predictions are purely random initially.
- Weights don’t “mean” anything yet.
- Example:
weights = np.random.randn(n_features)
2.Forward Propagation (Use Current Weights to Make a Guess)
- Weight Usage: We compute a weighted sum of inputs:
z=w1x1+w2x2+…+b
Activation: Sigmoid or softmax turns the raw score into probability.
Impact:
- If weight w1 is high and x1=1 the prediction leans towards spam.
- If weights are wrong, predictions will be far off.
Role of Weights Here: They define the slope of decision → higher weight = stronger influence from the corresponding feature.
3.Loss Computation (Measure How Bad the Guess Was)
- Loss Example (Binary Cross Entropy):
![]()
Impact:
- High loss → current weights led to a poor prediction.
- Low loss → current weights are doing well.
Role of Weights Here: Indirect; they set up the prediction that determines the loss.
4.Backpropagation (Blame the Right Weights)
- Gradient Calculation:
- Impact:
- If weight led to overprediction, it gets reduced.
- If it underpredicted, it increases.
- Features with higher values (x_i) affect weight change more.
- Interpretation:
- We learn which features were pushing the prediction in the wrong direction.
- Effect:
- Backprop gives precise responsibility scores to each weight.
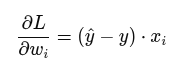
5. Weight Update (Small Fixes for Big Gains)
- Update Rule:
- Impact:
- Weights move a little closer to the “truth.”
- The model now knows “this feature should matter more/less.”
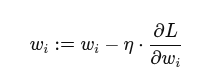
6. Repeat for Many Samples (Training Epochs)
- Weights are updated over:
- Many samples → generalization
- Many epochs → refinement
- Early Training:
- Weights change rapidly.
- Impact:
- We go from chaotic guesses → fine-tuned predictions.
7. Final Prediction (Learned Weights in Action)
- Weights now:
- Encapsulate which input features matter.
- Reflect complex interactions (in deeper nets).
- Impact:
- High weights = strong signals for prediction.
- Zero/low weights = ignored features.
3. Example of How Weight Affects Output
Let’s see an illustrative simulation with printed weights:
# After 0, 10, and final epoch
print(f”Initial Weights: {initial_weights}”)
print(f”After 10 Epochs: {weights_epoch_10}”)
print(f”Final Weights: {final_weights}”)