LeCun Initialization applicability in Neural Network
1. What is LeCun Initialization?
LeCun Initialization is a weight initialization method optimized for activation functions like sigmoid or tanh, which are common in shallow networks or non-ReLU settings.
Key Point:
- Helps control the variance of activations across layers.
- Ensures gradients don’t vanish or explode during training.
It works by initializing weights W from a normal distribution:
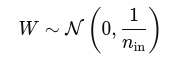
Where:
- ninn_{\text{in}}nin = number of input units to the neuron
| Scenario | Use LeCun Initialization? | Why? |
|---|---|---|
| Activation = tanh / sigmoid | Yes | Controls signal size to prevent vanishing |
| Small networks (1-2 layers) | Good | Keeps gradient flow stable |
| Using ReLU | No | Use He initialization instead |
Real-World Use Case: Stock Price Prediction
Imagine predicting the next-day closing price using past 5 days’ prices (sliding window). For a simple shallow neural network using tanh activations, LeCun initialization helps maintain balanced gradients and activations.
1. What is Vanishing Gradient?
It happens during backpropagation, where we adjust weights using gradients:
But if the gradient (partial derivative) is very small, this update becomes nearly zero.
2. Why tanh/sigmoid cause vanishing gradients?
Both tanh and sigmoid have flat regions in their curves where their derivatives are very close to zero.
tanh(x):
As ∣x∣|x|∣x∣ increases, tanh saturates to -1 or +1 → derivative ≈ 0.
sigmoid(x):
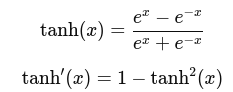
Same story: If input is far from 0, derivative becomes tiny.
Consequence:
If we’re using many layers:
- Gradients get multiplied many times with small numbers (like 0.01 or 0.1)
- They shrink exponentially
- This leads to almost no learning in early layers
3. In Stock Price Prediction – Why It Hurts
Suppose we’re using a 3-layer feedforward network to predict tomorrow’s stock price based on 5 past days.
What happens?
- We feed in prices: [105, 107, 106, 108, 110]
- Data passes through 3 layers using tanh activation
- During backpropagation, suppose gradients become:
- Layer 3: 0.05
- Layer 2: 0.01
- Layer 1: 0.0005
- So, Layer 1 (close to input) learns almost nothing — this means:
- Our network cannot understand deeper patterns across days
- It becomes biased toward recent values, not sequence trends
4. How LeCun Initialization Helps
LeCun initialization ensures that weights are small enough to avoid entering those “saturated” zones of tanh/sigmoid.
Let’s explain it visually:
Imagine a tanh curve:
-3 -----|-----------|-----------|----- +3
-0.995 0 +0.995
If input to tanh is:
- Too big (say +5) → output ≈ 1 → derivative ≈ 0 → no learning
- Well-controlled (say 0.5) → output ≈ 0.46 → derivative ≈ 0.79 → healthy learning
LeCun idea:
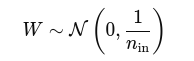
Ensures that signal starts small, around mean 0, inside the steep part of tanh/sigmoid curve.
Result:
- Activations don’t saturate
- Gradients stay useful
- Early layers learn meaningful features
- Overall training becomes smoother and faster
5. Real Stock Use Case Walkthrough
- We feed in 5-day windows of stock prices
- A 3-layer tanh-based network predicts the next price
- Compare random init vs LeCun init
In random init:
- Early layer gradients die out
- Model learns only surface-level patterns
- Slower convergence
In LeCun init:
- Gradients flow better
- Layer 1 learns how past prices shape trends
- Better generalization to unseen sequences
| Concept | Description |
|---|---|
| Vanishing Gradient | Gradients shrink as they’re backpropagated through layers |
| Why It Happens | Sigmoid/tanh derivatives ≈ 0 for large inputs |
| Effect on Stock Model | Early layers (closer to past days) don’t learn — hurting sequence learning |
| LeCun Helps Because | It scales weights to keep activations in active gradient zone |
| Real Benefit | Allows stable learning in tanh/sigmoid-based networks |
LeCun Initialization applicability in Neural Network – LeCun Initialization example with Simple Python