Error Reduction in Prediction of Result – Conceptual Steps in Neural Network
1. Intuition: Why Error Reduces After Each Epoch
Think of training a neural network like teaching a child to throw a ball into a basket:
- First attempt: The ball misses — too far.
- Feedback: We tell the child, “That was too strong.”
- Adjustment: Next time, the child throws with less force.
- Over time, this trial-error-feedback-adjustment loop helps the child improve.
Similarly, in a neural network:
- It makes a guess (prediction) using current weights.
- It measures how wrong that guess is (error/loss).
- It adjusts its weights to do better next time.
Mathematical Basis: How It Happens
Let’s formalize this in neural network language:
1. Loss Function: Measuring How Wrong We Are
We calculate Loss (Error) between prediction y^ and true label y. A common loss: Mean Squared Error (MSE) for regression tasks.
n
Loss = 1 / n∑(yi−y^i)^2
i=1
2. Gradient Descent: Finding the Direction to Reduce Error
We want to minimize the loss, so we use gradient descent:
- Calculate the gradient (slope) of the loss w.r.t. each weight www
- This tells us how the loss changes when the weight changes
∂Loss / ∂w
3. Weight Update Rule: Learn from Mistakes
We update weights in the opposite direction of the gradient:
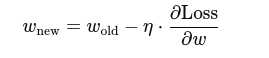
η is the learning rate — how big a step we take.
This moves the weight in the direction that reduces the error.
4. Epochs: Repeating the Process
An epoch means we’ve passed through the entire dataset once.
- After each epoch, we’ve had many chances to adjust weights
- If we keep doing this:
- Predictions improve
- Loss reduces
- Weights move toward optimal values
What Causes Error to Decrease Over Epochs?
| Reason | Explanation |
|---|---|
| Gradient points toward error reduction | Gradients indicate how to change weights to reduce loss |
| Small step-by-step learning | Learning rate ensures weights are not changed drastically |
| Data coverage in each epoch | Seeing full dataset helps generalize learning |
| Feedback loop | Each prediction error leads to better weight tuning |
Caveats: When Error Doesn’t Reduce
- Too high learning rate → overshoots optimal weights
- Too low learning rate → learning becomes very slow
- Model underfitting/overfitting → can’t learn or learns noise
- Poor initialization → can get stuck in local minima
Error Reduction in Prediction of Result Conceptual Steps in Neural Network – Error Reduction in prediction of Results with Simple Python