Basic Math Concepts – Xavier Initialization Applicability in Neural Network
| Concept | Explanation |
|---|---|
| Uniform Distribution | Values are chosen randomly between [-limit, +limit] |
| Variance Matching | Keeps output variance equal to input variance |
| ReLU Activation | Helps prevent vanishing gradient |
| Square Root Scaling | Derived from variance propagation through layers |
Xavier Formula Again:
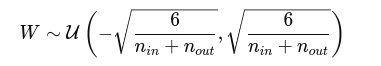
This is based on preserving variance:
- Variance of inputs ≈ Variance of outputs
- Helps stable gradient descent
Next – Sparse Initialization Applicability in Neural Network